本文以 Linux Kernel 5.15(commit 8bb7eca)为例进行分析。
Tldr
CVE-2022-0847 是一个因文件子系统中的零拷贝机制在处理
pipe_buffer时未初始化 flags,结合 splice 系统调用导致的漏洞。用户可以构造大量带有PIPE_BUF_FLAG_CAN_MERGE标志位的pipe_buffer并释放,接着调用 splice 函数从文件向管道填充数据,由于 flags 未正确初始化,将沿用之前的pipe_buffer的标志位。此时向管道中写入则可修改文件的 page cache。
代码分析
首先来看一下本次分析用到的结构体和重要的字段,这里可以先略过,等下文遇到的时候再作为字典查阅。可以直接跳转到函数部分。
pipe_inode_info
struct pipe_inode_info { // 存放了 pipe 机制所要用到的字段
...
// 标注队列首部的索引,这里的索引单位是 pipe_buffer。head 为接下来要写入的位置
unsigned int head;
// 标注队列尾部的索引。tail 为接下来要读取的位置
unsigned int tail;
// 最大可用的 pipe_buffer 个数,这个字段约束了整个 pipe 所能容纳的数据大小
unsigned int max_usage;
// 当前已分配的 pipe_buffer 个数,注意该值必须为2的幂
unsigned int ring_size;
...
// 结构体 file 引用至该管道的个数。这个有点类似某个管道被 dup 出多个 fd 一样
unsigned int files;
...
// 缓存先前被释放的 page,这个 page 可以被重用以降低重分配开销
struct page *tmp_page;
...
// 实际存放多个 pipe_buffer 的数组,在设计上我们需要将该一维数组看作一个环
struct pipe_buffer *bufs;
...
};其中,head 和 tail 的关系类似于
low addr high addr
+--------------------------------------------+
| | | | | | | | >|//|//|//|> | | | |
+--------------------------------------------+
A ----> A
| |
tail head
它们都指向没写满的 buffer。
pipe_buffer
struct pipe_buffer { // 存放着实际管道中存放的数据
struct page *page; // 对应的 page
// offset: 有效数据在 page 中的起始偏移
// len: 尚未被读取的有效数据的长度
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags; // 标志位
unsigned long private;
};可能的 flag 包含
#define PIPE_BUF_FLAG_LRU 0x01 /* page is on the LRU */
#define PIPE_BUF_FLAG_ATOMIC 0x02 /* was atomically mapped */
#define PIPE_BUF_FLAG_GIFT 0x04 /* page is a gift */
#define PIPE_BUF_FLAG_PACKET 0x08 /* read() as a packet */
#define PIPE_BUF_FLAG_CAN_MERGE 0x10 /* can merge buffers */
#define PIPE_BUF_FLAG_WHOLE 0x20 /* read() must return entire buffer or error */这里我们只需要关注 PIPE_BUF_FLAG_CAN_MERGE 标志。
iov_iter
struct iov_iter { // 用于迭代那种被分为多个页的数据
u8 iter_type; // 表示当前迭代的数据是来自于什么结构
bool data_source;
size_t iov_offset; // 当前所迭代到 page 的相对偏移,读写将从该 page 的这个相对偏移开始
size_t count; // 可读写的数组字节大小
union {
...
struct pipe_inode_info *pipe;
};
...
};iter_type 可能包含
enum iter_type {
/* iter types */
ITER_IOVEC,
ITER_KVEC,
ITER_BVEC,
ITER_PIPE, // 表示正在迭代的数据是位于 pipe 中的
ITER_XARRAY,
ITER_DISCARD, // 表示写入当前 iov_iter 的数据全部丢弃
};pipe_read
Tldr
pipe_read函数会循环从管道中读取数据,它会调用copy_page_to_iter将管道中的数据写入iov_iterto 结构中。
pipe_read 函数用于从管道中读取数据,它的大概流程为:
pipe_read
-> copy_page_to_iter
当内核需要从某个管道中读取数据时会调用 pipe_read 函数
- iocb: 存放着获取当前 pipe 结构体的指针
- to: 从管道读出来的数据将要写入的地方
static ssize_t
pipe_read(struct kiocb *iocb, struct iov_iter *to)
{从 to 中获取需要读入的数据大小:
size_t total_len = iov_iter_count(to);从 iocb 中获取 pipe_inode_info 结构体:
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
bool was_full, wake_next_reader = false;
ssize_t ret;如果读取大小为 0 则直接返回
/* Null read succeeds. */
if (unlikely(total_len == 0))
return 0;
ret = 0;
__pipe_lock(pipe);判断 pipe 是否已满,如果已满则设置 was_full 标志
was_full = pipe_full(pipe->head, pipe->tail, pipe->max_usage);循环读取 pipe 中的数据
for (;;) {
unsigned int head = pipe->head; // pipe 的头,指向的是 pipe_buffer
unsigned int tail = pipe->tail; // pipe 的尾
// 因为 pipe 是环形的,且 head 和 tail 可能大于 ring_size,所以需要计算 mask
unsigned int mask = pipe->ring_size - 1;
...如果管道中存在数据
if (!pipe_empty(head, tail)) {获取 tail 对应的 pipe_buffer。tail 可以大于 max_usage
struct pipe_buffer *buf = &pipe->bufs[tail & mask];chars 是当前管道中已有的数据大小
size_t chars = buf->len;
size_t written;
int error;如果当前管道已有数据大小大于用户需要读入的大小,则截断
if (chars > total_len) {
if (buf->flags & PIPE_BUF_FLAG_WHOLE) {
if (ret == 0)
ret = -ENOBUFS;
break;
}
chars = total_len;
}调用 pipe_buffer 的 confirm 方法,确认 pipe_buffer 中的数据有效
error = pipe_buf_confirm(pipe, buf);
...将当前 pipe buffer 所对应的内存页写入 to 中
written = copy_page_to_iter(buf->page, buf->offset, chars, to);如果写入大小小于可读的大小,说明在写入数据时出现不可恢复的错误,直接返回
if (unlikely(written < chars)) {
if (!ret)
ret = -EFAULT;
break;
}一轮读取完成
ret += chars; // 成功读取的字节数
buf->offset += chars; // 有效数据的偏移增长(因为被消耗了)
buf->len -= chars; // 还剩下的可读的数据减少如果是 packet buffer 的话,剩下的内容都扔掉
/* Was it a packet buffer? Clean up and exit */
if (buf->flags & PIPE_BUF_FLAG_PACKET) {
total_len = chars;
buf->len = 0;
}如果当前 pipe_buffer 中没有数据了,更新 tail 至下一个 pipe_buffer
if (!buf->len) {
pipe_buf_release(pipe, buf);
spin_lock_irq(&pipe->rd_wait.lock);
...
tail++;
pipe->tail = tail;
spin_unlock_irq(&pipe->rd_wait.lock);
}
total_len -= chars;如果读取完毕,跳出循环
if (!total_len)
break; /* common path: read succeeded */如果还需要读取数据,且管道中还有数据,继续循环
if (!pipe_empty(head, tail)) /* More to do? */
continue;
}
...
}接下来我们来看 copy_page_to_iter 相关函数。
copy_page_to_iter 相关
Tldr
copy_page_to_iter相关函数为“零拷贝”机制实现的部分
大体流程为:
copy_page_to_iter ->
__copy_page_to_iter ->
copy_page_to_iter_pipe
首先来看 copy_page_to_iter 函数:
// 零复制引用
size_t copy_page_to_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
size_t res = 0;
// 判断数据读写是否越界
if (unlikely(!page_copy_sane(page, offset, bytes)))
return 0;
page += offset / PAGE_SIZE; // first subpage
offset %= PAGE_SIZE;
while (1) {
size_t n = __copy_page_to_iter(page, offset,
min(bytes, (size_t)PAGE_SIZE - offset), i);
res += n;
bytes -= n;
if (!bytes || !n)
break;
offset += n;
if (offset == PAGE_SIZE) {
page++;
offset = 0;
}
}
return res;
}它会调用 __copy_page_to_iter 函数,这个函数会根据 iov_iter 的类型选择不同的函数:
static size_t __copy_page_to_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
// 根据 iov_iter 的类型选择不同的复制方式
if (likely(iter_is_iovec(i)))
return copy_page_to_iter_iovec(page, offset, bytes, i);
if (iov_iter_is_bvec(i) || iov_iter_is_kvec(i) || iov_iter_is_xarray(i)) {
...
}
if (iov_iter_is_pipe(i))
return copy_page_to_iter_pipe(page, offset, bytes, i);
if (unlikely(iov_iter_is_discard(i))) {
...
}
WARN_ON(1);
return 0;
}如果传入的 iov_iter 是 pipe 类型(也就是我们在研究的从管道中读取),会调用 copy_page_to_iter_pipe 函数:
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{获取待写入的 pipe 结构体
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;获取待写入的 pipe 结构体的一些信息,例如 head、tail等等
unsigned int p_tail = pipe->tail;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
size_t off;
... ...获取待写入的相对偏移位置
off = i->iov_offset;获取待写入数据的 pipe_buffer
buf = &pipe->bufs[i_head & p_mask];
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
i_head++;
buf = &pipe->bufs[i_head & p_mask];
}如果待写入的管道已满,则直接返回
if (pipe_full(i_head, p_tail, pipe->max_usage))
return 0;
buf->ops = &page_cache_pipe_buf_ops;增加该页的 refcount
get_page(page);直接引用已有的页,记录当前复制的 offset、len 等,以降低性能开销
buf->page = page;
buf->offset = offset;
buf->len = bytes;CVE-2022-0847: 未初始化 buf 中的 flags 字段
由于 pipe_buf 直接引用了已有的页,需要在 pipe_write 中保证新传来的数据不会写入这样的页面中。这种保证依赖于 flags 中的
PIPE_BUF_FLAG_CAN_MERGE字段,但这里并未对 flags 做初始化,因此它会使用之前的 flags 的值。
pipe->head = i_head + 1;
i->iov_offset = offset + bytes;
i->head = i_head;
out:
i->count -= bytes;
return bytes;
}
Danger
在零拷贝实现的过程中,如果页存在则只会对该页的 refcount 加一(
get_page)。但是在这里我们看见,新的pipe_buffer字段中,大部分内容都正确地初始化了,唯有buf->flags没有被初始化!
copy_to_iter 相关
Tldr
与
copy_page_to_iter不同,copy_to_iter被设计为从内核任意地址复制数据,因此该复制是 deep copy。
大体流程为
copy_to_iter
-> _copy_to_iter
-> copy_pipe_to_iter
-> push_pipe
// 数据复制,源数据类型可以是任意内核虚拟地址
static __always_inline __must_check
size_t copy_to_iter(const void *addr, size_t bytes, struct iov_iter *i)
{
if (unlikely(!check_copy_size(addr, bytes, true)))
return 0;
else
return _copy_to_iter(addr, bytes, i);
}在 _copy_to_iter 函数中,也存在不同的 iov_iter 处理方式:
size_t _copy_to_iter(const void *addr, size_t bytes, struct iov_iter *i)
{
if (unlikely(iov_iter_is_pipe(i)))
return copy_pipe_to_iter(addr, bytes, i);
...
return bytes;
}我们这里还是只关注对 pipe 的处理方式。进入 iov_iter_is_pipe,它会从内核中指定的地址复制任意类型的数据到 pipe 中:
static size_t copy_pipe_to_iter(const void *addr, size_t bytes,
struct iov_iter *i)
{获取要写入的 pipe 结构体:
struct pipe_inode_info *pipe = i->pipe;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head;
size_t n, off;
if (!sanity(i))
return 0;- 准备空间,n 为待写入数据字节大小
bytes = n = push_pipe(i, bytes, &i_head, &off);如果没有数据需要写入,则直接返回
if (unlikely(!n))
return 0;- 复制数据,这里会循环写入管道,直到待写入的数据全部写完。每写一次时,要么写完一整页,要么没写完一页就直接退出
do {
size_t chunk = min_t(size_t, n, PAGE_SIZE - off);
memcpy_to_page(pipe->bufs[i_head & p_mask].page, off, addr, chunk);
i->head = i_head;
i->iov_offset = off + chunk;
n -= chunk;
addr += chunk;
off = 0;
i_head++;
} while (n);最后修改当前 iov_iter 待写入的大小:
i->count -= bytes;
return bytes;
}其中 push_pipe 是我们要关注的重点,它会获取要写入的大小并准备对应的页:
static size_t push_pipe(struct iov_iter *i, size_t size,
int *iter_headp, size_t *offp)
{获取接收数据的 pipe
struct pipe_inode_info *pipe = i->pipe;
unsigned int p_tail = pipe->tail;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int iter_head;
size_t off;
ssize_t left;
...
left = size;data_start 获取 pipe 的 head & 起始 offset。这个函数用于过滤 head 指向上一个未被分配的 pipe_buffer 或者 offset == PAGE_SIZE 的情况
data_start(i, &iter_head, &off);
*iter_headp = iter_head;
*offp = off;如果当前是从某个页的中间位置开始写
if (off) {
// 判断这剩余的页够不够写
left -= PAGE_SIZE - off;
// 要是够写则直接返回
if (left <= 0) {
pipe->bufs[iter_head & p_mask].len += size;
return size;
}
// 如果不够写则先把该可写的半页,扩充为可写的整页
pipe->bufs[iter_head & p_mask].len = PAGE_SIZE;
iter_head++;
}到这里时循环扩充页
while (!pipe_full(iter_head, p_tail, pipe->max_usage)) {
// 循环获取 pipe_buffer,并初始化 pipe_buffer 结构体上的数据
struct pipe_buffer *buf = &pipe->bufs[iter_head & p_mask];
struct page *page = alloc_page(GFP_USER);
if (!page)
break;这里 buf 引用的页是上面申请的新页,会在后面通过 memcpy_to_page 填充
buf->ops = &default_pipe_buf_ops;
buf->page = page;
buf->offset = 0;
buf->len = min_t(ssize_t, left, PAGE_SIZE);CVE-2022-0847
和上文一样,这里也未对
buf->flag初始化,buf->flag将沿用旧的pipe_buffer的值
left -= buf->len;
iter_head++;
pipe->head = iter_head;
if (left == 0)
return size;
}
return size - left;
}简单总结一下当目标为 pipe 时,copy_page_to_iter 和 copy_to_iter 这两个函数:
| copy_to_iter | copy_page_to_iter | |
|---|---|---|
| 源数据类型 | const void *addr (任意内核虚拟地址) | struct page *page |
| 核心函数 | copy_pipe_to_iter | copy_page_to_iter_pipe |
| 内存操作 | 分配新页 | 引用现有页 |
| 数据移动 | 是(物理复制) | 否(零复制) |
| 主要函数调用 | push_pipe → alloc_page → memcpy_to_page | get_page |
pipe_buffer->ops | default_pipe_buf_ops | page_cache_pipe_buf_ops |
pipe_write
Tldr
pipe_write函数依靠PIPE_BUF_FLAG_CAN_MERGE实现页的合并。如果一页之内就能写下会直接合并,否则会循环写入pipe_buffer。
pipe_write 函数用于向管道中写数据:
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
unsigned int head;
ssize_t ret = 0;
size_t total_len = iov_iter_count(from);
ssize_t chars;
bool was_empty = false;
bool wake_next_writer = false;
...
__pipe_lock(pipe);
...
head = pipe->head;
was_empty = pipe_empty(head, pipe->tail);chars 保存了要写入的数据大小和页帧大小(PAGE_SIZE)的余数
chars = total_len & (PAGE_SIZE-1);如果 chars 不为 0 且 pipe_buffer 非空
if (chars && !was_empty) {
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[(head - 1) & mask];
int offset = buf->offset + buf->len;如果本次写入的数据可以 pipe_buffer 中剩余的空间容纳,且 buf 设置了 PIPE_BUF_FLAG_CAN_MERGE 标志位
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) &&
offset + chars <= PAGE_SIZE) {
ret = pipe_buf_confirm(pipe, buf);
if (ret)
goto out;通过零拷贝的方式将数据写入 pipe_buffer
ret = copy_page_from_iter(buf->page, offset, chars, from);
if (unlikely(ret < chars)) {
ret = -EFAULT;
goto out;
}
buf->len += ret;
if (!iov_iter_count(from))
goto out;
}
}如果本次的数据无法被单页容纳
for (;;) {如果 pipe 没有读者,说明管道已被破坏,发送 SIGPIPE 并退出
if (!pipe->readers) {
send_sig(SIGPIPE, current, 0);
if (!ret)
ret = -EPIPE;
break;
}
head = pipe->head;如果 pipe 没有被填满
if (!pipe_full(head, pipe->tail, pipe->max_usage)) {
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[head & mask];
struct page *page = pipe->tmp_page;
int copied;如果还没有为缓冲区分配页帧,调用 alloc_page() 函数分配一个
if (!page) {
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
if (unlikely(!page)) {
ret = ret ? : -ENOMEM;
break;
}
pipe->tmp_page = page;
}使用自旋锁锁住 pipe 的读者等待队列
/* Allocate a slot in the ring in advance and attach an
* empty buffer. If we fault or otherwise fail to use
* it, either the reader will consume it or it'll still
* be there for the next write.
*/
spin_lock_irq(&pipe->rd_wait.lock);
head = pipe->head;在加锁后检测 pipe 是否被填满(可能在加锁前被填满),如果被填满则进行下一次循环
if (pipe_full(head, pipe->tail, pipe->max_usage)) {
spin_unlock_irq(&pipe->rd_wait.lock);
continue;
}这个 pipe_buffer 要被写入了,因此将 pipe_buffer 中的 header 指向下一个,以避免并发写入同一个 pipe_buffer
pipe->head = head + 1;
spin_unlock_irq(&pipe->rd_wait.lock);向新的 pipe_buffer 中写入数据
/* Insert it into the buffer array */
buf = &pipe->bufs[head & mask];
buf->page = page;设置匿名管道操作
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;如果 fd 设置了 O_DIRECT,则每次写入时都会占用新的一页,而不会合并
if (is_packetized(filp))
buf->flags = PIPE_BUF_FLAG_PACKET;
else
buf->flags = PIPE_BUF_FLAG_CAN_MERGE;
pipe->tmp_page = NULL;复制页数据
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
...
ret += copied;
buf->offset = 0;
buf->len = copied;
if (!iov_iter_count(from))
break;
}
...
}
out:
if (pipe_full(pipe->head, pipe->tail, pipe->max_usage))
wake_next_writer = false;
__pipe_unlock(pipe);
...
return ret;
}
do_splice
Linux 库函数 splice 的作用是,将某个 fd 的数据不经过用户层,直接拷贝进另一个 fd 中。其函数声明如下:
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h>
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);这里的 fd 只能有两种情况:pipe fd 或 file fd,因此在 do_splice 函数中,内核也会对 fd 的类型做特判,来执行不同的数据传递操作。
在内核中会调用到 do_splice 函数,它的签名为:
/*
* Determine where to splice to/from.
*/
long do_splice(struct file *in, loff_t *off_in, struct file *out,
loff_t *off_out, size_t len, unsigned int flags)这里,我们只需关注 in-fd 为 file,out-fd 为 pipe ,即数据从文件传递至管道的情况:
在 5.15 版本中,调用链为
do_splice
-> splice_file_to_pipe
-> do_splice_to
在 do_splice_to 中,会根据文件系统类型调用对应的 splice_read 函数。
/*
* Attempt to initiate a splice from a file to a pipe.
*/
static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
// 根据文件系统类型,来调用对应的 splice_read 函数
unsigned int p_space;
int ret;
...
/* Don't try to read more the pipe has space for. */
// 获取待传递数据的大小
p_space = pipe->max_usage - pipe_occupancy(pipe->head, pipe->tail);
len = min_t(size_t, len, p_space << PAGE_SHIFT);
...
return in->f_op->splice_read(in, ppos, pipe, len, flags);
}我们接下来以 ext4 文件系统为例继续跟踪,ext4 的文件设置的调用类型为
const struct file_operations ext4_file_operations = {
...
.read_iter = ext4_file_read_iter,
...
.splice_read = generic_file_splice_read,
...
};generic_file_splice_read 函数的调用链为
generic_file_splice_read # fs/splice.c
-> call_read_iter # include/linux/fs.h
call_read_iter 也会调用特定于文件系统类型的函数:
static inline ssize_t call_read_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
return file->f_op->read_iter(kio, iter);
}在 ext4 中会调用 ext4_file_read_iter 函数。接下来的调用链为
ext4_file_read_iter # fs/ext4/file.c
-> generic_file_read_iter # mm/filemap.c
-> filemap_read # mm/filemap.c
-> copy_page_to_iter # lib/iov_iter.c
在 filemap_read 函数中,在有页缓存的情况下,会调用 copy_page_to_iter 通过零拷贝的方式将文件缓存页上的数据拷贝进 pipe 中。
利用流程
在有了上面的基础分析后,我们可以想一下已有的条件。
pipe_write依赖于PIPE_BUF_FLAG_CAN_MERGE标志位的设置;- 在
copy_page_to_iter_pipe和push_pipe等函数中,在初始化pipe_buffer时并没有初始化其中的 flags 字段,而是沿用旧的 flags 字段;
那么攻击流程大概是:
- 让所有的
pipe_buffer带有PIPE_BUF_FLAG_CAN_MERGE标志位并释放; - 将只读文件的部分数据(小于一页的长度)读入 pipe 中;
- 这一步由
copy_page_to_iter_pipe完成,flags 仍保留了PIPE_BUF_FLAG_CAN_MERGE标志,而 page 则指向了文件缓存页;
- 这一步由
- 向 pipe 中写入数据
- 由于 pipe 带有
PIPE_BUF_FLAG_CAN_MERGE标志,因此pipe_write会数据写入pipe_buffer的 page 中
- 由于 pipe 带有
这样,此时的文件缓存页就已经被我们改写了。
漏洞验证
这里用 https://github.com/n3rada/DirtyPipe 进行验证。
我们主要要验证两点
- 在 pipe_buffer 创建时,所有的 flags 字段都被填充为
PIPE_BUF_FLAG_CAN_MERGE; - 在 splice 调用时,
copy_page_to_iter函数中,flags 字段都未被初始化,使用之前的值(即PIPE_BUF_FLAG_CAN_MERGE)
首先创建一个要覆写的文件并用随机字符串填充:
root@debian-vm:~# tr -dc A-Za-z0-9 < /dev/random | head -c 64 > /flag
root@debian-vm:~# cat /flag
SdKnIt6p0WpqYIwHDlmVGDeU1dMTS8JaxXMqdrwM244wZUFuluIhtFoGA3wwKyxv在 Linux 中,pipe 的 ring_size 一般为 16(通过 fcntl(p[1], F_GETPIPE_SZ)),也就是说最多能填充 16 页一共 64K 大小的空间。
我们先用 write 填充满这些空间,再用 read 读,接着调用 slice,此时进入
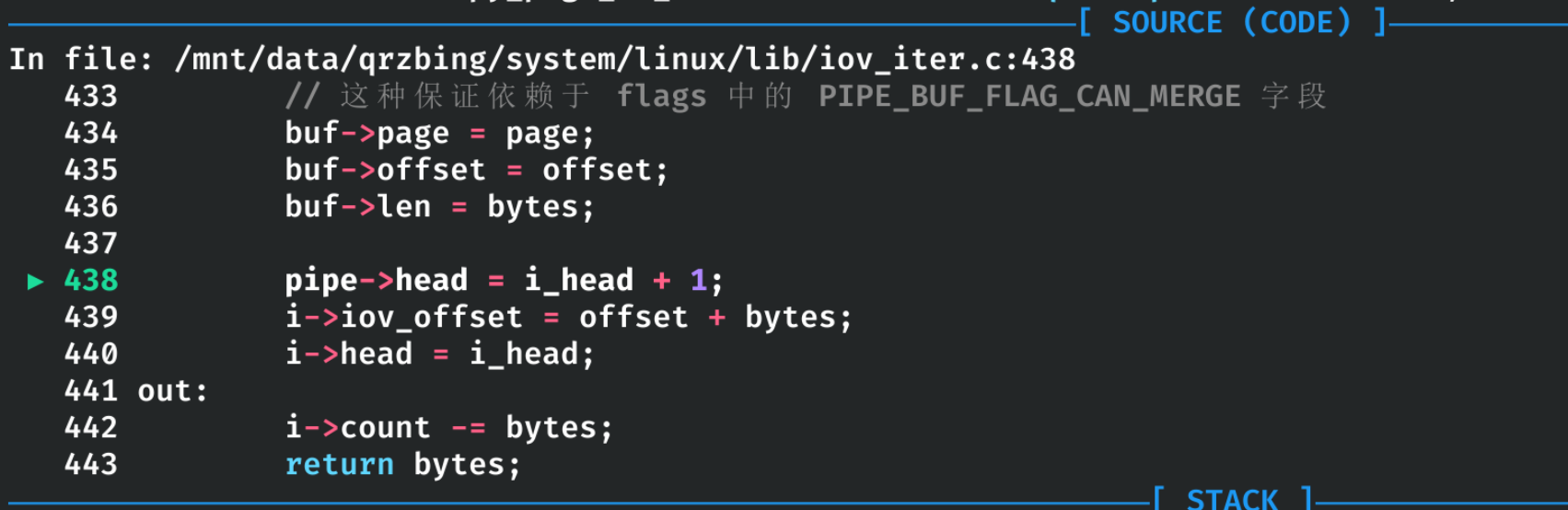
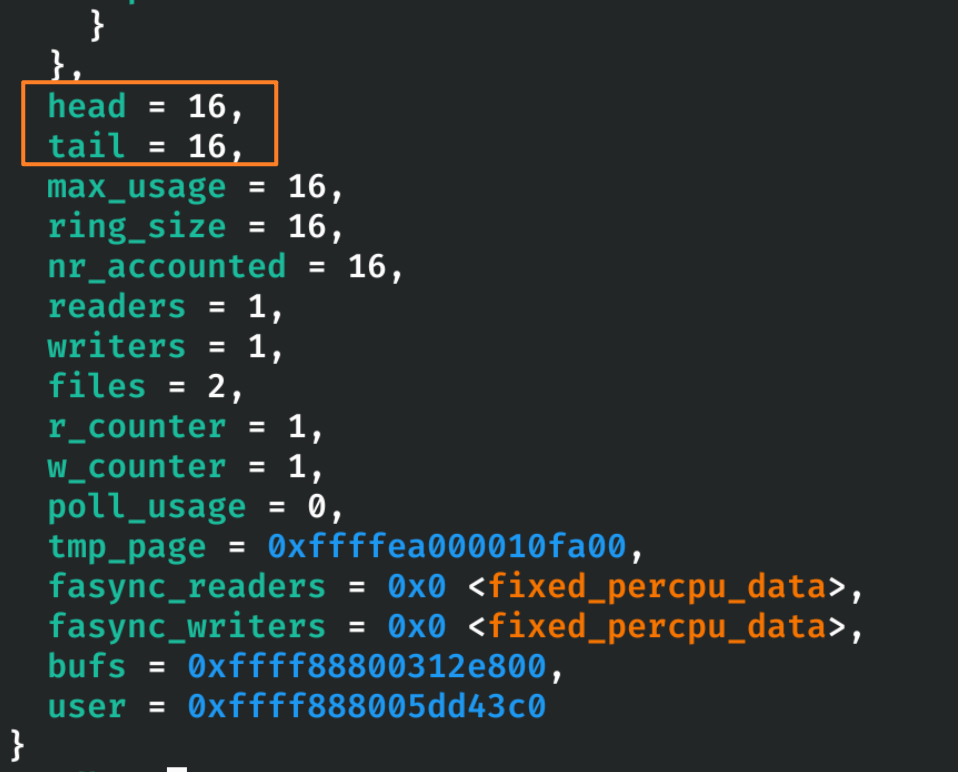
由于此时还没有写数据,当前的 pipe 为空(head==tail):
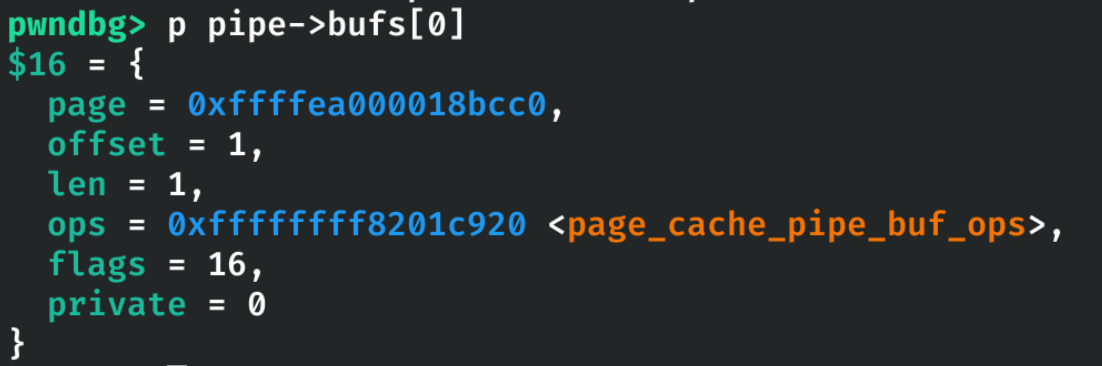
又因为没有正确初始化 buf->flags 结构,其值仍为之前设置的 PIPE_BUF_FLAG_CAN_MERGE(0x10):
在这一次写入中,可以成功触发 pipe 的合并操作(因为我们写的内容不超过一页):
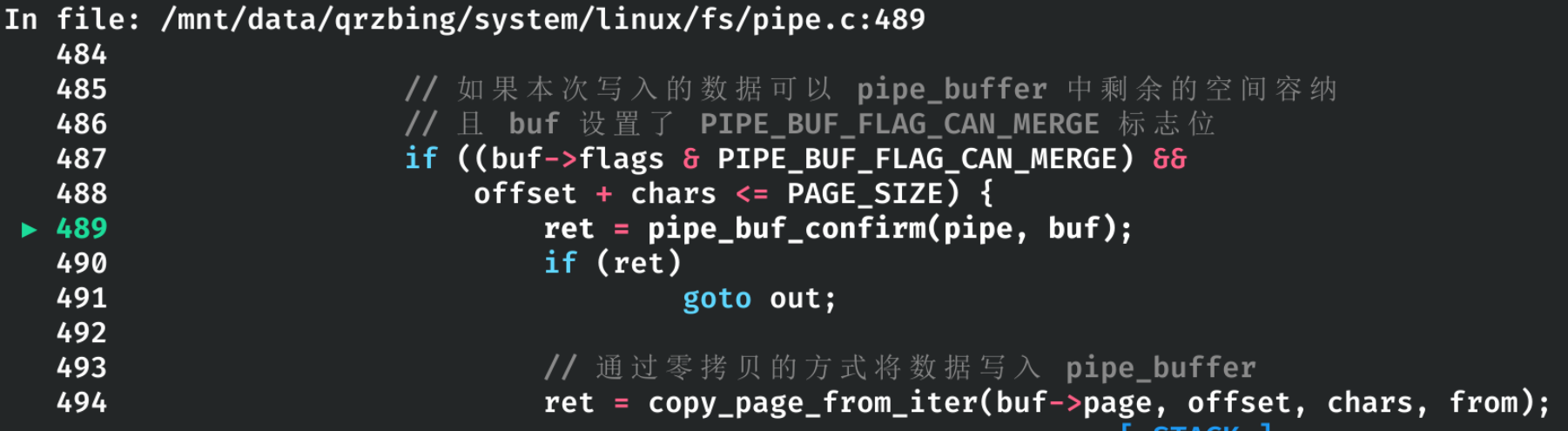
至此,漏洞验证完成。
漏洞成因
该漏洞由两个 commit 引入:
- new iov_iter flavour: pipe-backed - 241699c
- 引入字段的未初始化漏洞
- pipe: merge anon_pipe_buf*_ops - f6dd975
- 引入
PIPE_BUF_FLAG_CAN_MERGE标志位判断pipe_buffer是否是可合并的
- 引入
漏洞修复
在 lib/iov_iter: initialize “flags” in new pipe_buffer - 9d2231c 中进行了修复:将上述 copy_page_to_iter_pipe 和 push_pipe 函数中未初始化的 flags 位置零。
参考资料
- The Dirty Pipe Vulnerability
- Linux 内核 DirtyPipe 任意只读文件覆写漏洞(CVE-2022-0847)分析
- Linux Dirty Pipe CVE-2022-0847 漏洞分析
一篇早该写完的文章,断断续续拖到了现在……不过写完总比继续拖延要强,不是吗。