真是一对苦命鸳鸯

前置知识
CVE-2016-5195
见 CVE-2016-5195 Linux 内核内存子系统条件竞争漏洞
Linux 内存分页历史
分页机制的本质是建立虚拟地址到物理地址的映射索引。在早期的 8 位或 16 位处理器中,寻址范围有限(如 ),且多用于单任务环境,处理器通常直接访问物理内存。然而,现代操作系统为了支持多任务并发和内存保护,直接寻址已不再适用。
为此,我们在虚拟地址和物理地址之间引入了一层中间结构——页表(Page Table)。当 CPU 访问内存时,硬件(MMU)会先以虚拟页号为索引查询页表,获取对应的物理页号,再与页内偏移量求和最终访问实际的物理内存。图示这种通过一次查表即可完成映射的机制,正是一级页表。
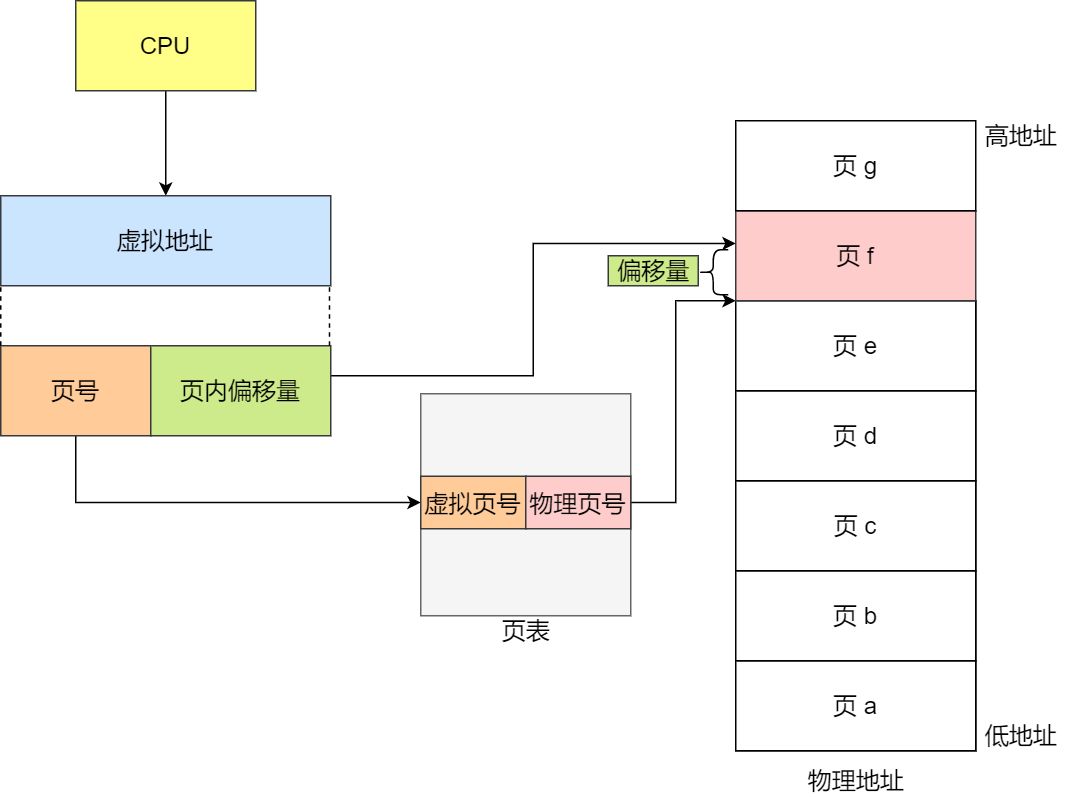
在一级分页下,每个页表项只能对应内存中的一个地址。假设一页的大小为 4KB(),一共有 4GB()内存,那么就有 个页。假设每个页表项的大小为 4 字节,那么每个都需要 4MB(2^18)大小的空间保存页表项,在多进程的环境下会占用恐怖的空间。因此,人们在一级页表的基础上引入了多级页表的概念。
以二级页表为例,它将 32 位分为 10 位一级页号,10 位二级页号和 12 位页内偏移,也就是说最多可以有 1024 个一级页表,每个一级页表又可以索引 1024 个二级页表,如下图所示:
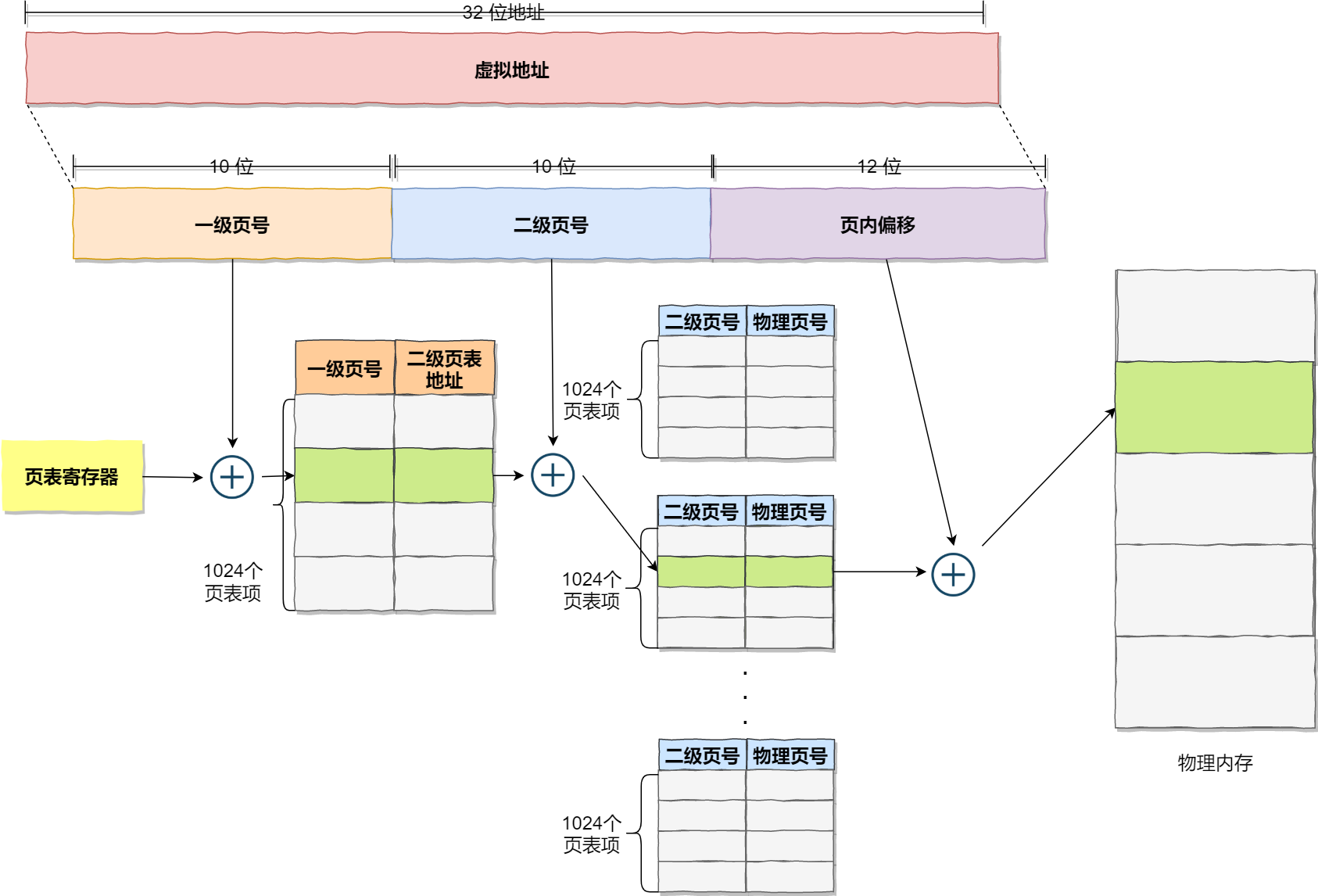
这样,如果一级页表没有创建,就不必创建对应的二级页表。假设只用到了 20% 的全部一级页表,也只有 4KB(一级页表) + 20% * 4MB(二级页表)= 0.804MB,大大降低了空间占用。
自从 2.6.10 开始,Linux 引入了四级页表,这使得用户可以操作最大 128 TB 的内存。它的寻址模型为:
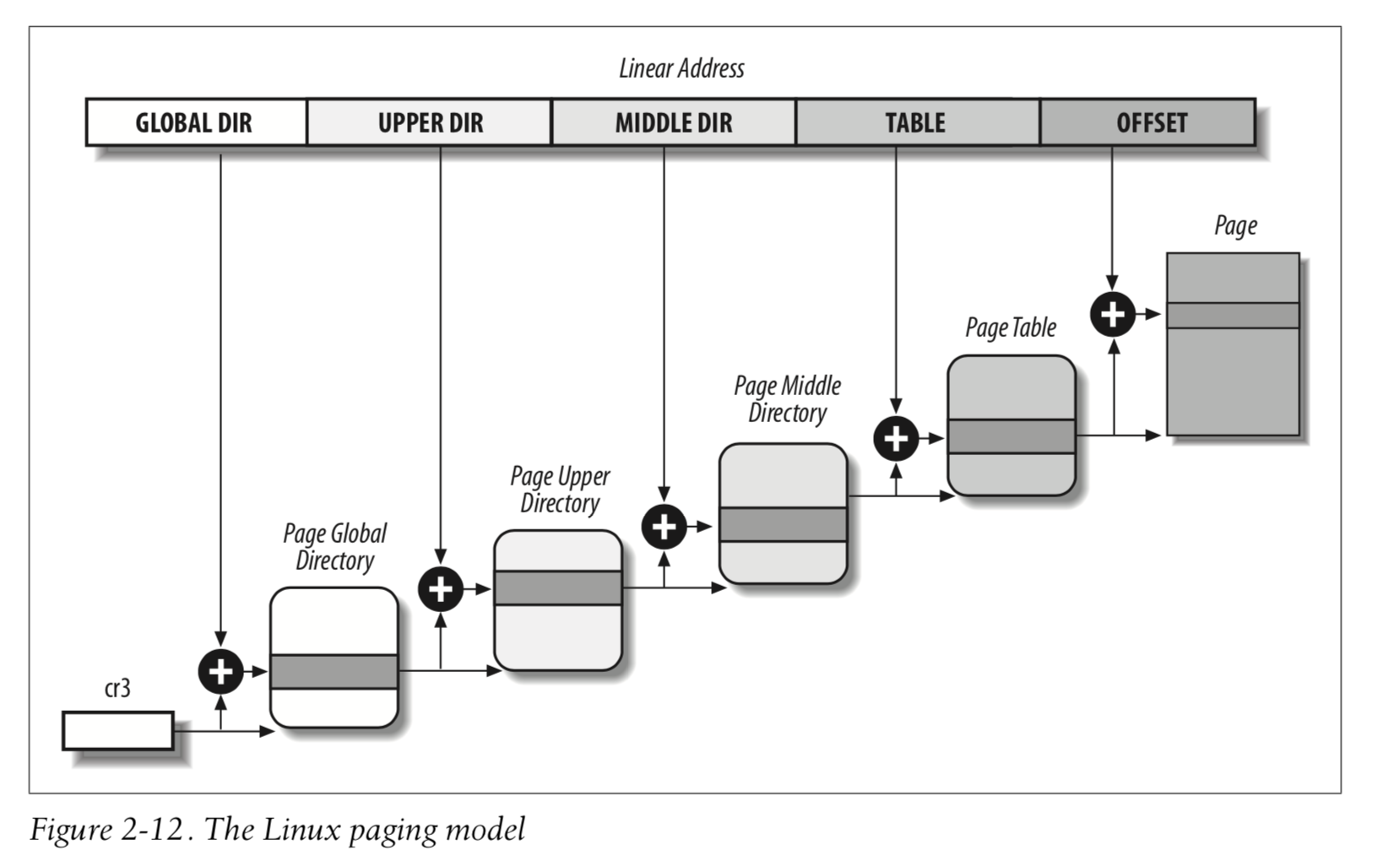
它包含四级目录,分别是:
- Page Global Directory, PGD:全局页目录项
- Page Upper Directory, PUD:上层页目录项
- Page Middle Directory, PMD:中间页目录项
- Page Table Entry, PTE:页表项
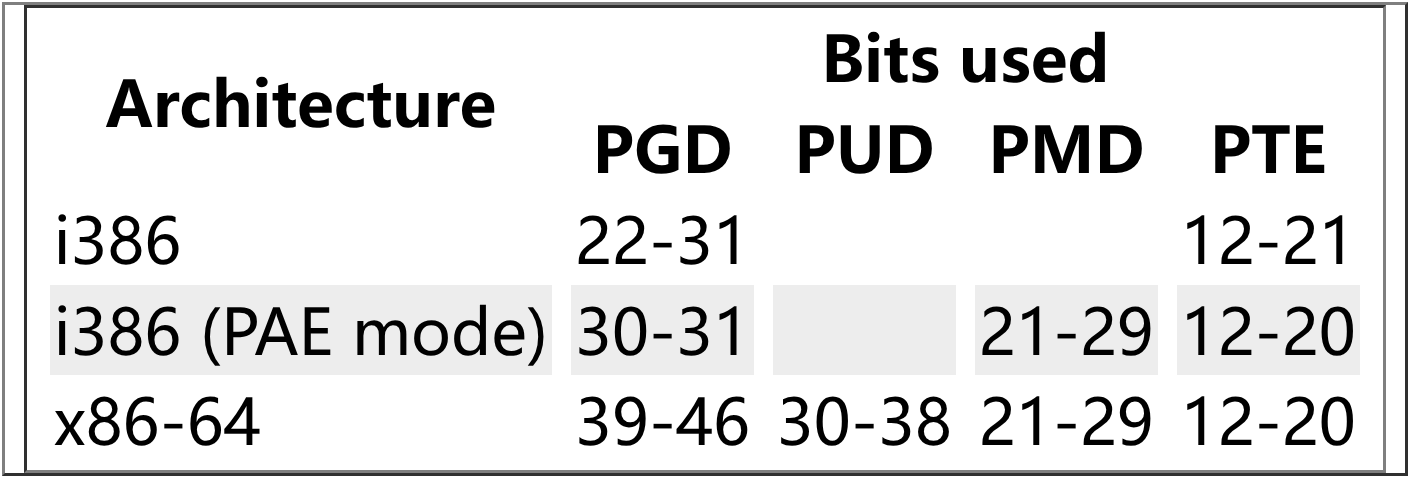
在 i386 模式下默认使用两级页表,PAE 模式下使用三级页表,x86-64 下使用四级页表,一共使用了 46 位。
而从 4.12 开始,Linux 引入了五级页表,将虚拟地址空间的限制提升到了 128 PB。程序员在 PGD 和 PUD 之间添加了 P4D(Page 4th Directory)页表项,如下图所示:
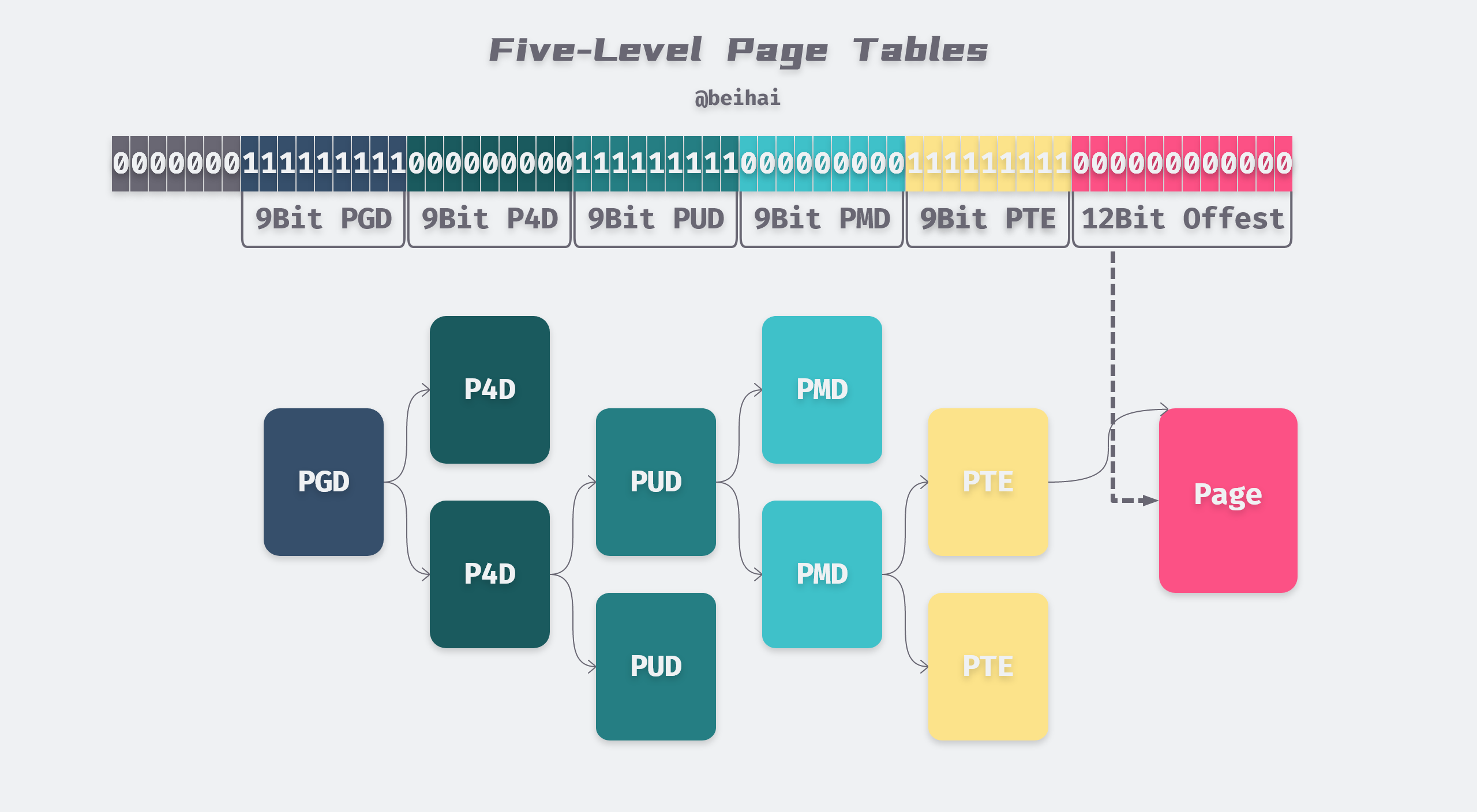
一共使用了 57 bit 表示一个虚拟地址。
大页内存管理
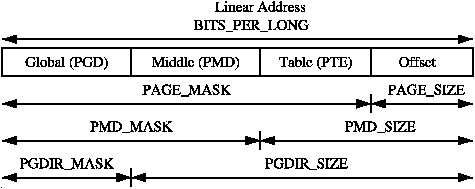
在 Linux 中,常见的内存页大小为 4KB。但为了满足系统和程序的特殊需求,在 x86 上,Linux 允许 2MB 或 1GB 的大内存页(Huge Page),按照上面的页表项,2MB 的大内存页其实就是将 PTE 和 offset 合并(21 Bit,2MB)PMD 作为页表项,1GB 的内存页就是 PUD 作为页表项,PMD、PTE、offset 合并为偏移,如下图所示
漏洞成因
我们在 Commit 8310d48 上进行分析。
还记得在 CVE-2016-5195 中,我们是如何将一个页面置为脏页的吗?如果不记得的话,可以在这里进行回顾。简单来说,在我们尝试对只读页面写入时,会因为缺页收获内核分配的一张只读且不可写的脏页。在后文中,由于竞争关系会去除 flags 中的 FOLL_WRITE,让内核以为需要只读页,返回给 kmap 一个真实可写的页。
在修复中,由于 POLL_WRITE 一直存在,fault_flag 始终包含 FAULT_FLAG_WRITE,之后就不会返回只读的页了。
总的来说,为了利用漏洞,我们需要在 __get_user_pages 函数中 follow_page_mask 时返回一张可用的页:
static long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *nonblocking)
{
...
retry:
...
cond_resched();
page = follow_page_mask(vma, start, foll_flags, &page_mask);
// 一般情况下第一次是不会映射到物理内存的,会进入 faultin_page
if (!page) {
int ret;
ret = faultin_page(tsk, vma, start, &foll_flags,
nonblocking);
...
return i;
}而在对 huge page 的 DirtyCow 修复中,最开始像往常一样为 huge page 添加了和 can_follow_write_pte 类似的代码:
+/*
+ * FOLL_FORCE can write to even unwritable pmd's, but only
+ * after we've gone through a COW cycle and they are dirty.
+ */
+static inline bool can_follow_write_pmd(pmd_t pmd, unsigned int flags)
+{
+ return pmd_write(pmd) ||
+ ((flags & FOLL_FORCE) && (flags & FOLL_COW) && pmd_dirty(pmd));
+}
+
struct page *follow_trans_huge_pmd(struct vm_area_struct *vma,
unsigned long addr,
pmd_t *pmd,
@@ -1138,7 +1154,7 @@ struct page *follow_trans_huge_pmd(struct vm_area_struct *vma,
assert_spin_locked(pmd_lockptr(mm, pmd));
- if (flags & FOLL_WRITE && !pmd_write(*pmd))
+ if (flags & FOLL_WRITE && !can_follow_write_pmd(*pmd, flags))
goto out;
/* Avoid dumping huge zero page */在 CVE-2016-5195 中,在竞争条件下,madvise 会释放页面,新申请的页自然就不带有脏位标记,can_follow_write_pte 检查也就无法通过。但是对于 huge page 也会这样吗?有没有可能还有一种其他办法设置脏位标记呢?
我们还需要考虑设置脏位的时机。follow_page_mask 会返回可用的页,而在前两次页故障中 flags 被设置为 FOLL_FORCE | FOLL_COW。那么我们最好在读的时候设置页面脏位,这样就可以过上面的那个 check 了。这可能吗?
作者 bindecy 真的找到了一条路径:touch_pmd 函数会无条件设置脏页
static void touch_pmd(struct vm_area_struct *vma, unsigned long addr,
pmd_t *pmd)
{
pmd_t _pmd;
/*
* We should set the dirty bit only for FOLL_WRITE but for now
* the dirty bit in the pmd is meaningless. And if the dirty
* bit will become meaningful and we'll only set it with
* FOLL_WRITE, an atomic set_bit will be required on the pmd to
* set the young bit, instead of the current set_pmd_at.
*/
_pmd = pmd_mkyoung(pmd_mkdirty(*pmd));
if (pmdp_set_access_flags(vma, addr & HPAGE_PMD_MASK,
pmd, _pmd, 1))
update_mmu_cache_pmd(vma, addr, pmd);
}而且仅需设置 FOLL_TOUCH 标志:
...
if (flags & FOLL_TOUCH)
touch_pmd(vma, addr, pmd);
...接下来的问题是该怎样触发?跟随 follow_page_mask,如果我们想访问的是大页,会调用 follow_trans_huge_pmd 函数:
struct page *follow_page_mask(struct vm_area_struct *vma,
unsigned long address, unsigned int flags,
unsigned int *page_mask)
{
...
*page_mask = 0;
page = follow_huge_addr(mm, address, flags & FOLL_WRITE);
...
pgd = pgd_offset(mm, address);
...
pud = pud_offset(pgd, address);
...
pmd = pmd_offset(pud, address);
...
// 普通的页,寻找 pte 项
if (likely(!pmd_trans_huge(*pmd)))
return follow_page_pte(vma, address, pmd, flags);
ptl = pmd_lock(mm, pmd);
...
page = follow_trans_huge_pmd(vma, address, pmd, flags);
spin_unlock(ptl);
*page_mask = HPAGE_PMD_NR - 1;
return page;
}在 follow_trans_huge_pmd 函数中,如果我们通过读的方式请求,也会调用 pmd_page 函数:
struct page *follow_trans_huge_pmd(struct vm_area_struct *vma,
unsigned long addr,
pmd_t *pmd,
unsigned int flags)
{
struct mm_struct *mm = vma->vm_mm;
struct page *page = NULL;
...
if (flags & FOLL_WRITE && !can_follow_write_pmd(*pmd, flags))
goto out;
...
if (flags & FOLL_TOUCH)
touch_pmd(vma, addr, pmd);
...注意到虽然上面有 flags & FOLL_WRITE 的检查,但读的方式就足够给页表项上脏位标记了!
而 FOLL_TOUCH 标记会在 get_user_pages 中就默认设置,也免去了我们寻找赋值路径的麻烦。
long get_user_pages(unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas)
{
return __get_user_pages_locked(current, current->mm, start, nr_pages,
pages, vmas, NULL, false,
gup_flags | FOLL_TOUCH);
}
EXPORT_SYMBOL(get_user_pages);攻击流程
这样,攻击流程就很清晰了,甚至和 CVE-2016-5195 毫无区别:
- 写入线程:写只读内存区域,通过两次页故障获得
FOLL_WRITE | FOLL_COW标志位; - 读取线程:条件竞争,
madvise释放掉私有页 - 读取线程:发起读取操作,为页表项设置脏页标志;
- 写入线程:通过
follow_page_mask通过上述检查,获得只读页; - 写入线程:通过 kmap 的方式进行强行写入,完成漏洞利用。
PoC 也很清晰明了,在此不多加赘述了。
补丁分析
Commit a8f9736 添加了若干代码,核心修改位于 touch_pmd 函数和 touch_pud 函数,不再无理由写脏位而是根据传入的 flags 进行判断,如果带有 FOLL_WRITE 请求才写脏位:
@@ -842,20 +842,15 @@ EXPORT_SYMBOL_GPL(vmf_insert_pfn_pud);
#endif /* CONFIG_HAVE_ARCH_TRANSPARENT_HUGEPAGE_PUD */
static void touch_pmd(struct vm_area_struct *vma, unsigned long addr,
- pmd_t *pmd)
+ pmd_t *pmd, int flags)
{
pmd_t _pmd;
- /*
- * We should set the dirty bit only for FOLL_WRITE but for now
- * the dirty bit in the pmd is meaningless. And if the dirty
- * bit will become meaningful and we'll only set it with
- * FOLL_WRITE, an atomic set_bit will be required on the pmd to
- * set the young bit, instead of the current set_pmd_at.
- */
- _pmd = pmd_mkyoung(pmd_mkdirty(*pmd));
+ _pmd = pmd_mkyoung(*pmd);
+ if (flags & FOLL_WRITE)
+ _pmd = pmd_mkdirty(_pmd);
if (pmdp_set_access_flags(vma, addr & HPAGE_PMD_MASK,
- pmd, _pmd, 1))
+ pmd, _pmd, flags & FOLL_WRITE))
update_mmu_cache_pmd(vma, addr, pmd);
}
@@ -995,20 +990,15 @@ int copy_huge_pmd(struct mm_struct *dst_mm, struct mm_struct *src_mm,
#ifdef CONFIG_HAVE_ARCH_TRANSPARENT_HUGEPAGE_PUD
static void touch_pud(struct vm_area_struct *vma, unsigned long addr,
- pud_t *pud)
+ pud_t *pud, int flags)
{
pud_t _pud;
- /*
- * We should set the dirty bit only for FOLL_WRITE but for now
- * the dirty bit in the pud is meaningless. And if the dirty
- * bit will become meaningful and we'll only set it with
- * FOLL_WRITE, an atomic set_bit will be required on the pud to
- * set the young bit, instead of the current set_pud_at.
- */
- _pud = pud_mkyoung(pud_mkdirty(*pud));
+ _pud = pud_mkyoung(*pud);
+ if (flags & FOLL_WRITE)
+ _pud = pud_mkdirty(_pud);
if (pudp_set_access_flags(vma, addr & HPAGE_PUD_MASK,
- pud, _pud, 1))
+ pud, _pud, flags & FOLL_WRITE))
update_mmu_cache_pud(vma, addr, pud);
}参考资料
CVE-2017-1000405 参考资料
Linux 内存分页历史参考资料
- Four-level page tables merged
- Five-level page tables
- 页表
- Linux中的分页机制
- CS 153 Design of Operating Systems - Lecture 18: Paging
- 揭开操作系统之内存管理的面纱
- Linux 系统中的虚拟内存