Tldr
- 检测目标:Linux 驱动
- 程序状态:
- 理论上是程序状态机中记录状态信息、控制状态(流)的变量;
- 实现中是类似 ioctl、mmap 等系统调用参数下能够影响控制流的变量。
这篇文章 fuzz 的目标是 Linux 上的驱动程序。
先看一下概要:
- 执行相同路径的代码不应被丢弃,因为它可能触发了不同的状态
- 本文通过状态变量对程序进行建模,在 fuzzing 时跟踪这些变量的值推断程序状态,优先考虑触发新状态的测试用例
- 实验表明可以提升代码覆盖率和状态覆盖率
那么我的问题是:
- 可以想象到程序中有一些变量作为 StateFuzz 中的状态变量,那么它是怎么确定状态变量的呢?
- 根据第 2.3 节,在开发的过程中开发者就会用到状态机,因此可以从状态机中选择保存状态的变量作为状态变量。
- 那么接下来看一下程序状态的建模吧(第 3.1 节)
- 状态变量:
- 生存期长,可以记录状态信息
- 可以由用户更新,进行状态转换
- 应该能够直接或间接影响控制流或内存访问指针
- 程序状态:如果保存所有状态那数量太多,该怎么优化呢?
- 只考虑程序状态中的相关变量对(互相影响的变量);
- 将值空间转换为多个值范围,相当于是降维了。
- 如果发现了新的值范围边缘或新的极值,则认为发现了新状态
- 状态变量:
架构
接下来看一下 StateFuzz 架构:
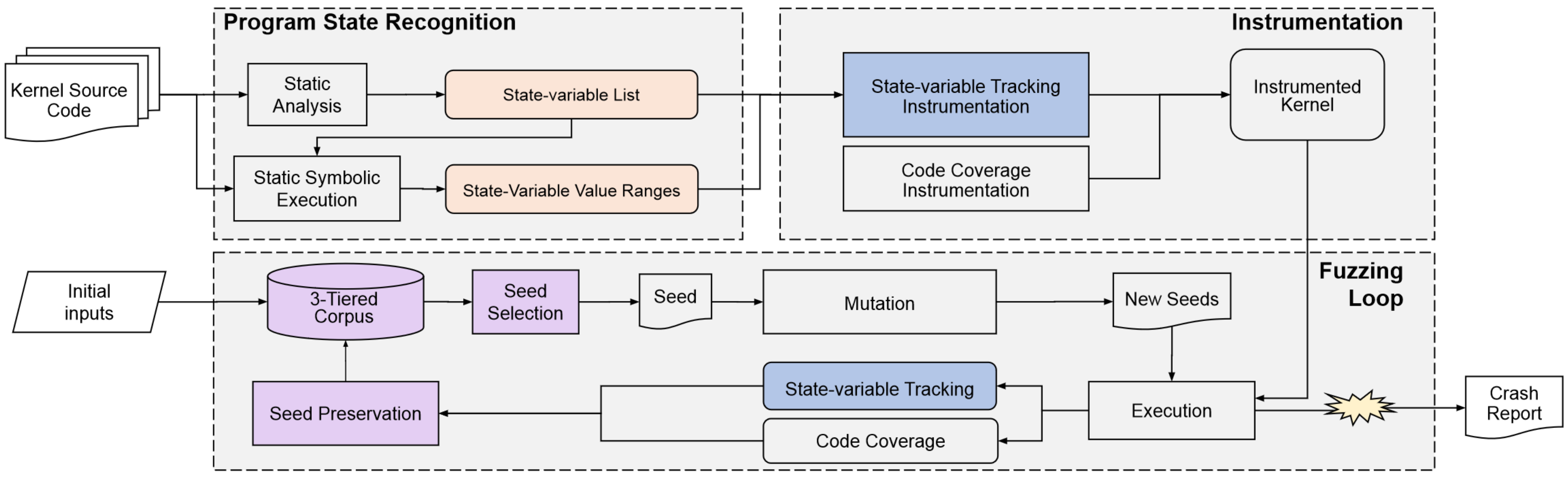
猜测
涂色的部分是本文的工作,简单猜测 StateFuzz 的工作流程:
- 对内核源码进行静态分析获得状态变量列表
- 将状态变量列表结合符号执行获得状态变量值的边缘(也就是默认定义一些状态)
- 结合状态变量列表和状态变量值范围进行状态变量的插桩而后进行 fuzzing
推测对种子进行的操作:
- 在执行后,如果发现了新状态,那么根据状态对种子进行生成和选择。
结合一下论文验证一下猜想对不对吧。看看 3.2 节的整体概括,StateFuzz 分为三部分:
- 程序状态识别
- 通过分析 Linux 源码提取状态变量、值的范围和状态变量的相关性
- 静态分析找变量
- 符号执行找范围和相关性
- 通过分析 Linux 源码提取状态变量、值的范围和状态变量的相关性
- 程序插桩
- 通过 SVF 在编译期间识别状态变量别名,跟踪状态变量在 fuzz 中所有值的变化
- Fuzzing 循环
- 大概就是怎样利用程序状态去更新种子了
现在的问题是:
- 既然程序状态这么多,作者是用什么方法选取的?
看看第 3.3 节,程序状态的识别分为三个阶段:
- 程序行为识别
- 主要是识别类似 ioctl、mmap 系统调用的 flags 参数,然后识别系统调用实现中 flag 对应的操作下面的变量。作者们通过拓展 Difuze 识别的程序行为。
- 程序状态识别
- 作者们识别程序调用图中的代码及访问的变量。如果变量可以回溯到全局变量或者某个结构体的字段,就标记这些变量(因为状态变量应该有较长的生命周期)
- 筛选出所有变量后,根据程序行为进行筛除,没有被任何程序行为调用的都被排除
- 推断程序值的范围
- 在 AST 阶段进行符号执行,推测是用 CSA 跑的过程间的符号执行,然后根据求解出的变量的约束划分值的范围。
一个状态变量示例实例:
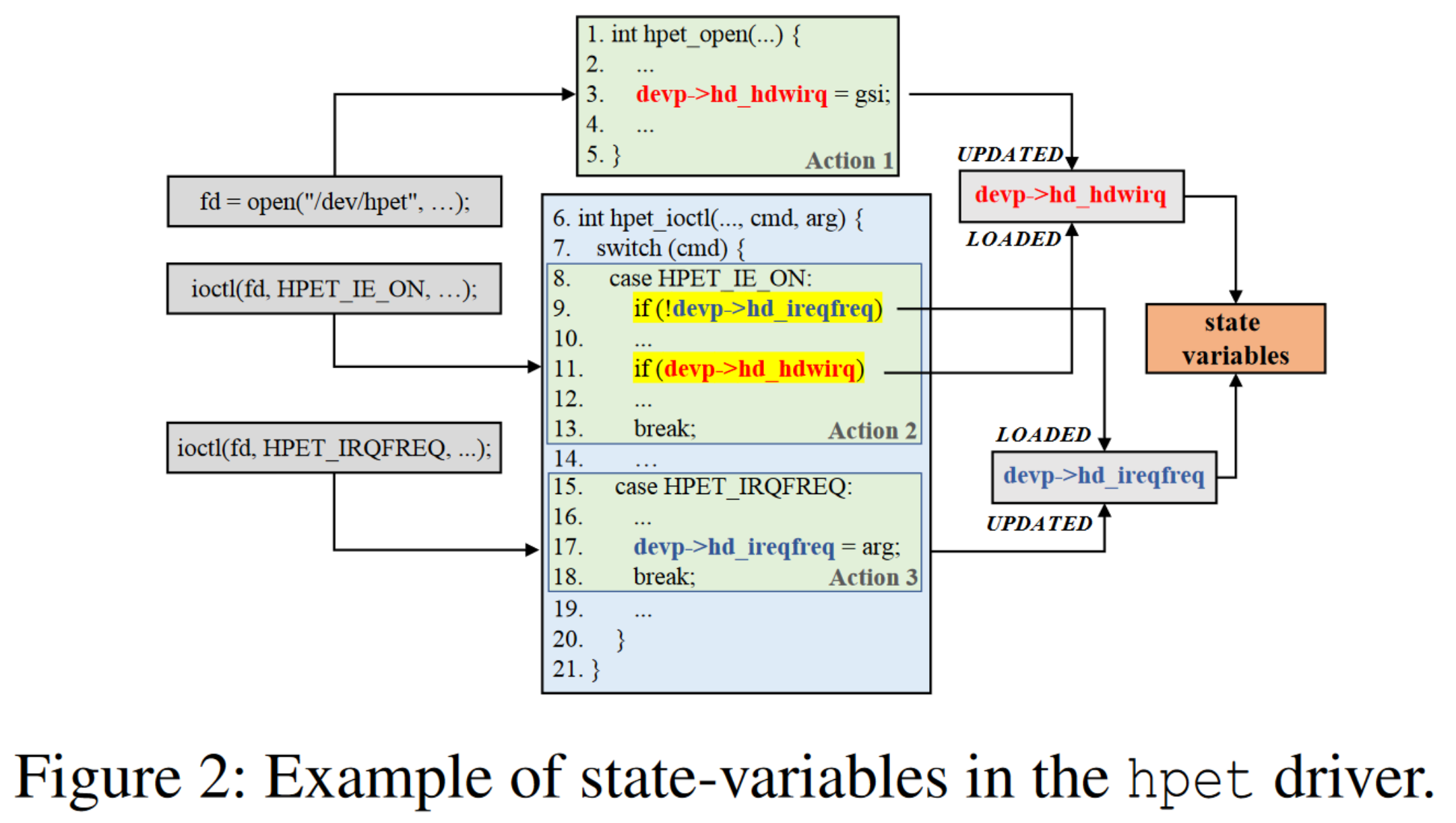
简单来说就是 ioctl 参数下可以控制执行流的变量。
第 3.4 节是对 fuzzing 循环的介绍:
- 三维反馈机制,包括代码覆盖率、取值范围和极值。
- 问题来了,取值范围和极值有什么区别
- 看上去极值是整个取值范围的上限和下限
- 问题来了,取值范围和极值有什么区别
- 种子保存策略
- 也是三层,对应三种反馈机制
- 种子选择策略
- 避免局部最优,让三种种子均匀地被选择
实现
- 通过 Difuze 识别程序行为,LLVM pass 识别状态变量,CRIX 建立调用图,CSA 收集变量范围和极值;
- SVF 查找状态变量别名,LLVM SanCov 检测覆盖率和状态;
- 基于 Syzkaller 实现 Fuzz 核心模块